
基于键值对数据库的高效轨迹相似查询方案 [ICDE-2022论文]
Published:
相似性搜索已成为许多轨迹数据分析任务的重要组成部分。随着物联网技术的快速发展,使得企业收集轨迹数据的途径变多、速度变快,导致许多轨迹分析任务必须从海量轨迹中寻找相似的轨迹。由于轨迹数据结构复杂,具有不规则的空间形状和连续的时间序列属性,存储和查询海量轨迹数据具有挑战性。西南交通大学博士生、京东实习生何华均为第一作者,郑宇教授和李天瑞教授为通讯作者,重庆大学李瑞远副教授、京东智能城市研究院-时空实验室鲍捷和何天赋,以及西安电子科技大学阮思捷博士共同完成的论文《TraSS: Efficient Trajectory Similarity Search Based on Key-Value Data Stores》提出了一种在key-value数据库中快速查询相似轨迹的高效方案。通常,海量轨迹数据可以通过key-value数据库进行管理。然而,现有的key-value数据库只能使用粗粒度的空间索引来存储轨迹数据,并且没有提供高效的查询处理算法来搜索相似的轨迹。TraSS提出了一种新颖的空间索引 XZ,它利用具有不同大小和不规则形状的索引空间来精细地表示轨迹的空间位置和形状。此外,TraSS设计了一个从 XZ 的多维索引空间到一维连续整数域的编码函数,可方便设计高效的轨迹存储策略和快速的轨迹查询处理算法。进一步地,为了提高相似性搜索的效率,TraSS采用两个步骤来修剪不相似的轨迹:(1)全局修剪。它利用 XZ* 索引来修剪没有相似于查询轨迹的索引空间。TraSS的全局剪枝只会挑选出与查询轨迹具有相似大小和形状的索引空间。与之前最先进的索引相比,TraSS的全局剪枝在查询处理过程中减少了高达 66.4% 的 I/O 开销;(2)局部过滤。它以降低相似度计算复杂度的方式来快速过滤不相似的轨迹。TraSS使用 Douglas-Peucker 算法从轨迹中提取代表性特征来加速局部过滤,极大地降低了查询处理过程中产生的计算量。大量实验和实际案例表明TraSS极大地提高了海量轨迹相似查询效率。
[本文总阅读量: 次]

相似性搜索已成为许多轨迹数据分析任务的重要组成部分。随着物联网技术的快速发展,使得企业收集轨迹数据的途径变多、速度变快,导致许多轨迹分析任务必须从海量轨迹中寻找相似的轨迹。由于轨迹数据结构复杂,具有不规则的空间形状和连续的时间序列属性,存储和查询海量轨迹数据具有挑战性。西南交通大学博士生、京东实习生何华均为第一作者,郑宇教授和李天瑞教授为通讯作者,重庆大学李瑞远副教授、京东智能城市研究院-时空实验室鲍捷和何天赋,以及西安电子科技大学阮思捷博士共同完成的论文《TraSS: Efficient Trajectory Similarity Search Based on Key-Value Data Stores》提出了一种在key-value数据库中快速查询相似轨迹的高效方案。通常,海量轨迹数据可以通过key-value数据库进行管理。然而,现有的key-value数据库只能使用粗粒度的空间索引来存储轨迹数据,并且没有提供高效的查询处理算法来搜索相似的轨迹。TraSS提出了一种新颖的空间索引 XZ,它利用具有不同大小和不规则形状的索引空间来精细地表示轨迹的空间位置和形状。此外,TraSS设计了一个从 XZ 的多维索引空间到一维连续整数域的编码函数,可方便设计高效的轨迹存储策略和快速的轨迹查询处理算法。进一步地,为了提高相似性搜索的效率,TraSS采用两个步骤来修剪不相似的轨迹:(1)全局修剪。它利用 XZ* 索引来修剪没有相似于查询轨迹的索引空间。TraSS的全局剪枝只会挑选出与查询轨迹具有相似大小和形状的索引空间。与之前最先进的索引相比,TraSS的全局剪枝在查询处理过程中减少了高达 66.4% 的 I/O 开销;(2)局部过滤。它以降低相似度计算复杂度的方式来快速过滤不相似的轨迹。TraSS使用 Douglas-Peucker 算法从轨迹中提取代表性特征来加速局部过滤,极大地降低了查询处理过程中产生的计算量。大量实验和实际案例表明TraSS极大地提高了海量轨迹相似查询效率。
1 背景
近年来,高速发展的物联网技术使我们能够轻松捕捉移动物体的轨迹。例如,京东6万多位快递员每天可产生超过1T的轨迹日志。如此庞大的轨迹数据需要高效且可扩展的数据管理方案。轨迹数据管理需要支持很多基础的查询操作。例如空间范围查询,它查找经过给定空间范围的轨迹;相似度查询,它查找与给定轨迹相似的所有轨迹。在这些查询中,轨迹相似性搜索是一种十分重要,但计算复杂的基本操作。例如,我们可通过寻找与传染病患者轨迹相似的轨迹来排查患者的密切接触者。轨迹相似性搜索也有利于拼车、轨迹聚类等轨迹分析应用。HBase等key-value数据库实现了大数据的快速写入/读取吞吐量,并可根据行键进行快速查找。因此,它们广泛用于管理大规模数据。现有一些工作利用key-value数据库管理轨迹大数据。然而,它们不能有效地提供轨迹相似性搜索,因为(1)它们以粗略的表示来存储轨迹;并且(2)它们缺乏有效的查询处理来搜索相似的轨迹。
1.1 表示:轨迹由一系列的多维时空点组成,但key-value数据库使用一维键值对存储对象。因此,我们必须为轨迹对象分配适当的一维键。现有工作使用空间索引,例如 R-trees来表示key-value数据库中的轨迹。它们将轨迹分配到许多索引空间中。每个索引空间都有一个空间边界,并配备了唯一的索引值。因此,我们可以使用该唯一值作为键的一部分来存储和查询轨迹。R-tree 及其变体等动态索引在插入大量数据时不可避免地会调整索引结构。因此,使用动态索引的现有工作在大规模轨迹数据管理中存在可维护性和可扩展性差的问题。由JUST、TrajMesa等工作证明,XZ-Ordering 是在key-value数据库中表示轨迹的更好选择。正如图1(a)(b) 中的箭头所示,XZ-Ordering可以被视为四叉树的扩展, 它将四叉树每个子空间的宽度和高度加倍,形成一个由四个子空间组成的索引空间。XZ-Ordering 利用最小的索引空间来表示轨迹的 MBR(最小边界框)。如图1 (b) 所示,T_1 由较大的索引空间(’00’)表示,而 T_3 由较小的索引空间(’303’)表示。然而,轨迹可能只出现在索引空间的一小部分,例如,T_1 占用其索引空间(“00”)的面积未超过一半。因此,XZ-Ordering 的索引空间对于许多轨迹来说仍然太粗略。导致,在查询时,查询处理很难仅通过修剪 XZ-Ordering 的索引空间来过滤掉不相似轨迹。
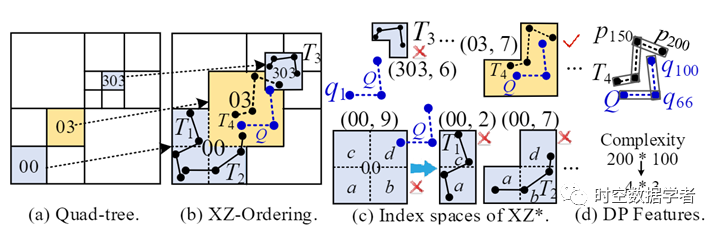
图1 轨迹的表示
1.2 查询处理:因为相似度度量往往相当复杂,所以计算两条轨迹的相似度非常耗时。因此,查询处理阶段有必要提前剔除尽可能多的不相似轨迹,以避免产生不必要的 I/O 开销和计算。扫描存储区域中的所有轨迹并计算它们与查询轨迹的相似度的过程虽实现简单但十分耗时。因此,查询处理阶段经常采用两个步骤来提高查询效率:(1)全局剪枝:避免访问不相关的存储区域。两条相似的轨迹极大可能在空间上彼此接近。因此,我们可以修剪在空间上远离查询轨迹的索引空间。通常,大多数现有空间索引的索引空间是一个能完全包含轨迹 MBR 的矩形。许多现有工作不会修剪与查询轨迹的 MBR 相交的索引空间,从而导致大量错误命中,进而产生不必要的 I/O 开销。如图1(b) 所示,T_1、T_2 和 T_3 是假命中,因为它们距离 查询轨迹Q 较远;(2) 局部过滤:以低复杂度的方式快速去除每个数据区域中的不同轨迹。现有工作使用 MBR 或轨迹的代表点(例如,起点和终点)来过滤不同的轨迹。然而,这些特征并不能精确地表示轨迹的空间形状,使得过滤效率不明显。因此,需要更精准的轨迹特征来快速过滤不相似的轨迹。
1.3 我们的解决方案:为了解决上述缺点,我们提出了TraSS,一个高效的大规模轨迹相似查询系统。图 2 概述了TraSS的框架。它的核心操作是轨迹表示和查询处理。
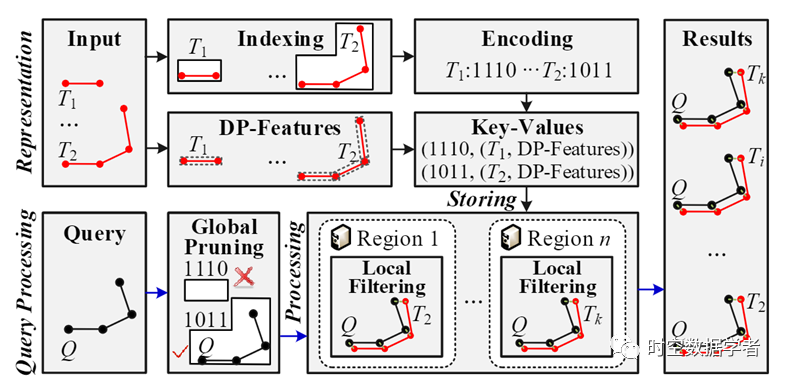
图2 TraSS示意图
(a)轨迹表示:我们提出了 XZ* 索引(图3),它提供了一个具有不规则形状的索引空间来表示轨迹。然后,我们用唯一的整数对每个索引空间进行编号,以便于存储和查询轨迹。此外,我们计算轨迹的代表性特征以加速查询处理。如图2所示,轨迹 T_1 和 T_2 由合适的索引空间索引,并配备 DP 特征(图4),最后转换为精准的编码(1110 和 1011)存储至Key-value数据库中。具体而言,我们提出的XZ* 索引能在同一索引空间内表示尽可能多的相似轨迹。它将XZ-Ordering的每个放大元素划分为四个相等的子区域,并利用子区域的组合作为索引空间。较大的索引空间用于覆盖较大的轨迹,而较小的索引空间用于覆盖较小的轨迹。此外,大小类似的轨迹可以通过它们的空间形状来区分。如图1(c)所示,我们将 XZ-Ordering 的放大元素 (00) 分成四等份 ,即a, b, c, d,然后使用组合它们代表不同形状的轨迹,例如,(00, 2) 和 (00, 7) 分别代表 T_1 和 T_2。此外,我们设计了一个双射函数,将索引空间转换为连续整数值,而不是在内存中维护索引结构。它比字符串编码消耗更少的存储开销,并提高了可维护性和可扩展性。
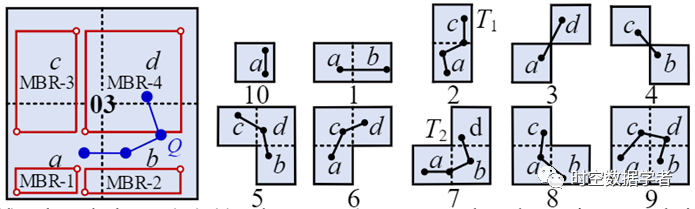
图3 XZ* index
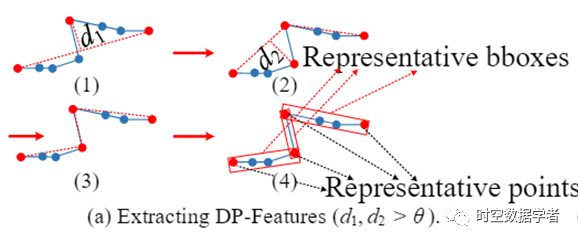
图4 DP-Features
(b) 查询处理:我们提供高效的查询处理以从数据库中快速查找相似的轨迹。如图2,给定一个查询轨迹Q,我们首先使用全局剪枝过滤掉不可能包含与查询轨迹相似轨迹的索引空间。然后,我们在每个存储区域上利用局部过滤消除剩余索引空间中不会成为最终结果的轨迹。我们的索引可以精确地描述一个轨迹的空间位置和形状。因此,我们只需要访问与查询轨迹Q相似的索引空间即可,进而避免访问与Q不相似的索引空间中的轨迹。直观地,比查询轨迹Q太大或太小的索引空间, 或者和 Q 大小相似但距离 Q 很远的索引空间可以直接被剪枝。如图1(c) 所示,’00’ 的 part- a 距离 Q 很远,因此可以剔除所有由 part-a 组成的索引空间。此外,在 图1(c) 中,Q 的 q1 远离 (303, 6) 的索引空间,这意味着 Q 不与所有位于(303, 6)中的轨迹相似。理论上,与最先进的解决方案相比,我们可以减少多达 83.6%的 I/O 开销。如图1(c) 所示,只有索引空间 (03, 7) 才能覆盖与 Q 相似的轨迹。此外,我们使用 DP (Douglas-Peucker) 算法从轨迹中提取代表点。该算法利用很少的点来近似轨迹的空间形状。此外,我们使用边界框来表示任意两个连续代表点之间的点。因为代表点和边界框的数量远小于轨迹中的点,所以我们可以快速过滤掉不同的轨迹。如图1(d) 所示,我们用四个点和三个边界框来表示一个 200 点的轨迹 T_4。p_{150} 是 T_4 的第三个代表点,它远离Q,所以我们可以快速消除T_4。最后,只有少数轨迹必须计算全局修剪和局部过滤后不可避免且耗时的相似度。
2 索引和存储
本节详细探讨如何在key-value数据库中利用XZ*索引来表示轨迹。索引包括两个主要操作,即索引结构和编码设计。然后,我们提取代表性特征以近似表示轨迹。最后介绍了如何存储轨迹。
2.1 索引结构
我们提出了一个细粒度的静态索引,即 XZ*,它可以近似地表示轨迹的形状。首先,我们使用四叉树的规则将整个空间分成许多不同分辨率的子空间,然后给每个子空间一个quadrant sequence。之后,受 XZ-ordering启发,我们将每个子空间的高度和宽度向右上角加倍,以覆盖不同大小的轨迹。最后,为了近似反映轨迹的形状,我们将放大后的元素平均分为四个子区域。我们使用子区域的组合作为索引空间来表示轨迹,并给每个组合一个 position code 来表示其在放大元素中的相关位置,如图5(e) 所示。这样,我们就可以用一个不规则的索引空间来细致地表示一条轨迹。

图5 XZ*
2.2 编码方案
Key-value数据库使用键值对的形式来存储数据。我们设计了一个双射函数来生成存储键以更好地支持轨迹数据存储和查询。我们双射函数编码的优点是:(1)轨迹的索引空间可以通过数学公式计算出来,而不需要维护内存中的索引结构。因此,我们可以减少轨迹管理系统的维护成本;(2)存储开销小于字符串编码。例如,对于 16 分辨率的索引空间,字符串编码需要 16 字节的象限序列和 1 字节的位置码,而我们的编码只需要 8 字节的整数,这样我们就可以减少键的存储开销 约 53%;(3) 使用简单的连接会使编码不连续,这样会增加查询时的key range搜索次数,降低性能。
我们的编码如下:

如图5(c) 和图5 (e) 所示,T_1 和 T_2 的索引值分别为 V(03, 2) = 40 和 V(03, 7) = 45。
V 是一个双射函数,因为每个索引空间只有一个索引值,而一个索引值只有一个索引空间。此外,象限序列和位置代码的字典顺序对应于索引值的不太等顺序,因此V保留了XZ*的空间特征。
2.3 DP-Features
现实世界中的轨迹可能包含很多点,因此相似度的计算成本很高。但是,许多连续点可能彼此非常接近。因此,我们使用 Douglas-Peucker (DP) 算法,在不影响精度的情况下减小轨迹的大小。DP是一种可以轻松实现的轨迹压缩算法,它可找到轨迹中具有代表性的点。此外,我们进一步提取可覆盖两个连续代表点之间所有点的边界框(缩写为bbox,它不一定平行于坐标轴),如图4(a)中所示的红色bbox( 4)。
2.4 存储方案
我们使用一个不规则的索引空间来表示一个轨迹,并为索引空间分配一个索引值。因此,我们可以使用索引值作为存储和查询轨迹的空间键。键组合如下,
rowkey = shards + index~value + tid,
其中 `+’ 是连接操作;shards是一个散列值,用于分散轨迹,可以避免热点问题;index value表示轨迹的空间信息,由 公式3计算而来;tid 是轨迹的唯一标识符。

表中给出轨迹表的结构,其中 tid 是标识符,points列存储轨迹的原始时空点。值得注意的是,为了有效地执行轨迹相似性搜索,我们还需要列来存储一些有价值的特征,例如,dp-points 记录代表点在原始轨迹的位置,dp-mbrs 存储DP 特征的 MBR。注意,大部分key-value存储都有自动分区策略,所以本文不再进一步设计分区策略。
3 查询处理
在本节中,我们将描述如何处理轨迹相似性查询。我们首先给出我们的主要思想。基于主要思想,提出了两种剪枝策略,即全局剪枝和局部过滤。此外,我们将展示剪枝策略如何改进两个典型的轨迹相似性查询,即 Threshold Similarity Search 和 Top-k Similarity Search。
3.1 主要思想:
轨迹按照表1的结构进行存储,并且通过行键进行搜索。每个行键都配有一个表示轨迹形状的索引值。查询处理旨在消除与查询轨迹不相似的索引空间,进而避免计算与不必要的轨迹的复杂相似性。我们设计了全局剪枝策略以巧妙地过滤掉包含与查询轨迹不相似的索引空间。本文通过放大的元素和位置代码表示一个索引空间。全局剪枝首先引理修剪掉不必要的放大元素,再利用策略来过滤掉剩余放大元素中不需要访问的位置代码。执行全局剪枝后,我们需要提取剩余的索引空间中覆盖的轨迹。为了减轻复杂相似度的计算,我们提出了基于代表性特征的局部过滤轨迹,可有效地过滤掉不同的轨迹。基于全局剪枝和局部过滤,我们实现中两个常用的相似性搜索,即 Threshold Similarity Search 和 Top-k Similarity Search。
3.2 全局剪枝:
轨迹具有空间形状。相似轨迹的形状通常与查询轨迹的形状相似。因此,不必要提取被太大或太小的索引空间索引的轨迹。因此, TraSS根据查询轨迹的空间形状,确定能包含相似轨迹的索引空间所处的最大和最小分辨率(maxR和minR),如图6(a)(b)所示。进而,查询处理可根据minR和maxR过滤掉太大或太小的enlarged elements。此外,TraSS可根据轨迹与enlarged element的距离,即minDistEE,剪枝不相似的enlarged element。enlarged element仍然太大而无法精准表示轨迹。因此,我们提出了位置码的概念,它使用四个子区域的组合作为索引空间。TraSS可根据轨迹形状和索引空间的关系,剪枝不相似的索引空间,如图7所示。详细的剪枝流程,请参考原文给出的定义、引理和证明。
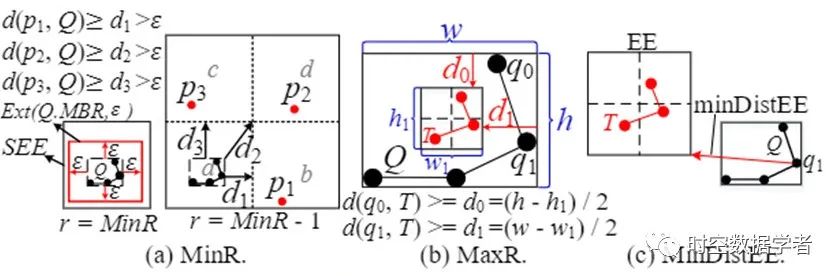
图6 剪枝EE
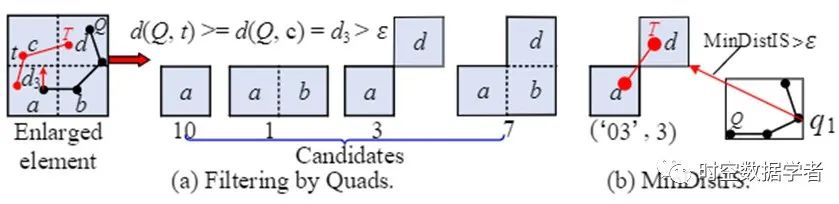
图7 剪枝索引空间
3.3 局部过滤:
过滤掉不必要的索引空间后,我们需要从key-value数据库中每个区域中提取候选索引空间索引的轨迹。TraSS设计的局部过滤将有助于以最小的计算成本剔除每个区域中的不相似轨迹。因为必须访问两条轨迹的所有点,所以计算两条轨迹的相似度非常耗时。因此,我们使用 DP 特征来精简地刻画表示轨迹,这可以有效地帮助查询处理过滤不同的轨迹,如图8(b)所示。详细的剪枝流程,请参考原文给出的定义、引理和证明。

图8 DP-Feature过滤
4 实现
如图9所示,我们基于 HBase(一种流行的key-value数据库)实现了 TraSS。首先,我们使用适当的索引空间对轨迹进行索引。然后,使用 Douglas-Peucker (DP) 算法来预先计算轨迹的 DP 特征。之后,我们将轨迹转换为 puts,并将所有 puts 插入 HBase 中。在执行相似度搜索时,我们首先计算查询轨迹的 DP 特征。然后,我们将全局修剪和局部过滤下推到 HBase 的协处理器中。最后,我们将查询结果返回给客户端。
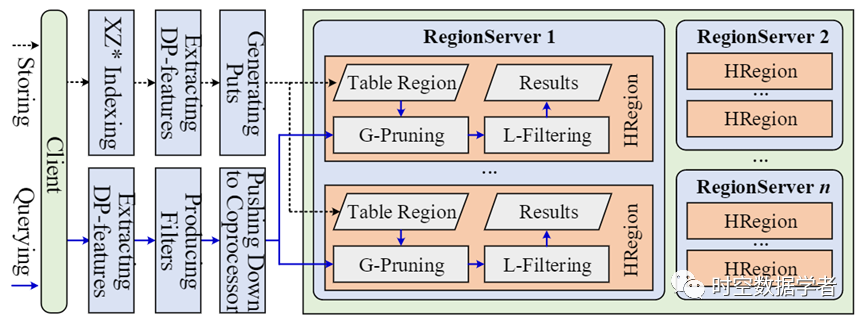
图9 基于HBase的TraSS实现
5 总结
本文提出了TraSS,一种基于key-value数据库的轨迹相似性搜索框架。我们利用 XZ* 索引精准地表示key-value数据库中的轨迹,并为 XZ* 提供高效的编码来存储和查询key-value数据库中的轨迹。我们设计了高效的全局剪枝和局部过滤策略,有效地避免了访问不相似的轨迹。大量实验表明, TraSS 优于最先进的分布式解决方案。较XZ-Ordering索引, XZ* 索引可降低高达 66.4%的I/O 开销。TraSS 支持许多轨迹相似性度量,例如 Frechet、Hausdorff 和 DTW。此外,XZ* 索引支持空间范围查询。未来工作包括如何支持其他指标和其他空间查询。
有关 TraSS 的更多详细信息,请参阅:https://huajunge.github.io/academicpages/publication/2022-03-23-paper-title-number-1
报告视频:https://huajunge.github.io/academicpages/talks/2022-05-10-TraSSS