
TraSS: Efficient Trajectory Similarity Search Based on Key-Value Data Stores
Published in ICDE, 2022
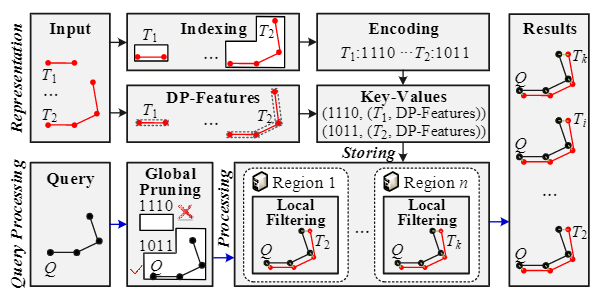
Abstract: Similarity search has recently become an integral part of many trajectory data analysis tasks. As the number of trajectories increases, we must find similar trajectories among massive trajectories, necessitating a scalable and efficient framework. Typically, massive trajectory data can be managed by key-value data stores. However, existing works with key-value data stores use a coarse representation to store trajectory data. Besides, they do not provide efficient query processing to search similar trajectories. Thus, this paper proposes TraSS, an efficient framework for trajectory similarity search in key-value data stores. We propose a novel spatial index, XZ, which utilizes fine-grained index spaces with irregular shapes and sizes to represent trajectories elaborately. Further, we devise a bijective function from the index spaces of XZ to continuous integers, which is simple but effective for query processing. To improve the efficiency of similarity search, we employ two steps to prune dissimilar trajectories: (1) global pruning. It leverages the XZ* index to prune index spaces with no trajectories similar to the query trajectory. Our global pruning can only pick out index spaces with similar sizes and shapes to the query trajectory. Compared to the state-of-the-art index, our global pruning reduces I/O overhead up to 66.4% during query processing; (2) local filtering. It filters dissimilar trajectories in a way with low complexity. We use a few representative features extracted from a trajectory by the Douglas-Peucker algorithm to accelerate the local filtering. We implement an open-source toolkit (TraSS) on a popular key-value data store. Extensive experiments show that TraSS outperforms state-of-the-art solutions.
Huajun He, Ruiyuan Li, Sijie Ruan, Tianfu He, Jie Bao, Tianrui Li, Yu Zheng. TraSS: Efficient Trajectory Similarity Search Based on Key-Value DataStores[C]//2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2022.